

Introduction to protein-nucleic acid interactions
DNA- and RNA-binding proteins (DRBPs) constitute a significant fraction of cellular proteins and have important roles in cells. Their functions include control of transcription and translation, DNA repair, splicing, apoptosis, and mediating stress responses (Hudson & Ortlund, 2014). Proteins interact with DNA and RNA through similar physical forces, which include:
- Electrostatic interactions (salt bridges),
- Dipolar interactions (hydrogen bonding, H-bonds),
- Entropic effects (hydrophobic interactions) and
- Dispersion forces (base stacking).
These forces contribute in varying degrees to proteins binding in a sequence-specific (tight) or non–sequence-specific (loose) manner. For example, an α-helix motif in the protein commonly mediates specific protein–DNA interactions by inserting itself into the major groove of the DNA. This allows it to recognize and interact with a specific base sequence through H-bonds and salt bridges. Additionally, protein oligomerization or multi-protein complex formation (e.g., transcription initiation complexes) can enhance the affinity and specificity of a particular protein–nucleic acid interaction. The secondary and tertiary structure formed by nucleic acid sequences (especially in RNA) provides an important additional mechanism by which proteins recognize and bind particular nucleic acid sequences. (Overview of Protein-Nucleic Acid Interactions | Thermo Fisher Scientific – IN)
Nucleic acid binding domains
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence (a recognition sequence) or have a general affinity to DNA. A typical protein has one or a few domains. Often the three-dimensional structure of the protein shows the domains folded into separate units. (Wikipedia, 26-10-2024)The DNA- or RNA-binding function of a protein is localized in discrete conserved domains within its tertiary structure. An individual protein can have multiple repeats of the same nucleic acid binding domain or can have several different domains found within its structure. The identity of the individual domains and their relative arrangement are functionally important within the protein. Nucleic acid-binding proteins are mostly composed of at least one DNA/RNA-binding domain that interacts in a specific or nonspecific manner. DNA-binding proteins such as transcription factors, DNA polymerases, histones, and DNA ligases can be represented by various DNA-binding domains carrying different molecular functions (Ghani et al., 2018). Several common DNA binding domains include:
- Zinc fingers,
- Helix-turn-helix,
- Helix-loop-helix,
- Winged helix, and
- Leucine zipper.
RNA-binding specificity and function are constituted by zinc finger, KH, S1, PAZ, PUF, PIWI, and RRM (RNA recognition motif) domains. Multiple nucleic acid binding domains with a single protein can increase the specificity and affinity of the protein for certain target nucleic acid sequences, mediate a change in the topology of the target nucleic acid, properly position other nucleic acid sequences for recognition or regulate the activity of enzymatic domains within the binding protein. (Overview of Protein-Nucleic Acid Interactions | Thermo Fisher Scientific – IN)
DNA recognition motifs
Helix-Turn-Helix Motif
The helix-turn-helix (HTH) motif is one of the most common motifs used by proteins to bind DNA, being found in approximately one-third of all DNA binding proteins. The proteins bind as dimers. 16–20-bp long unique stretches of DNA with dyad symmetry bind the protein dimers via two symmetrically spaced helix-turn-helix motifs. Each motif comprises two stretches of α-helices connected by a β-turn with an interhelical angle of about 90° (Adhya, 2001). The first α-helical motif lies across the major groove of DNA making hydrophobic interactions with the second helix, known as the recognition helix, which lies partly within the major groove and makes specific contact with DNA. The proteins are held in a stable ordered manner by an extensive array of hydrogen bonds. Mutations within this region allow dramatic changes in the specificity of DNA binding (Caramori et al., 2020).
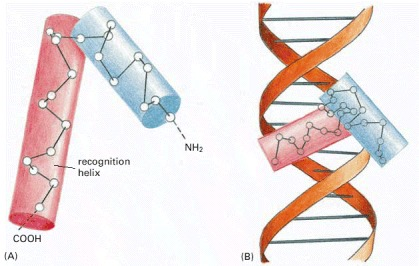
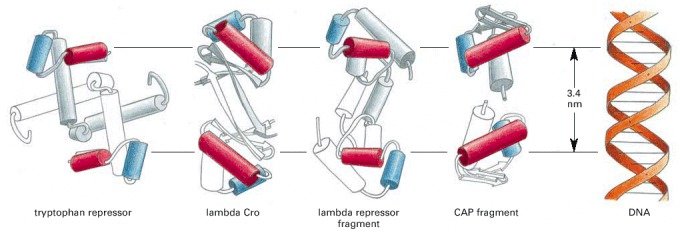
Some helix-turn-helix DNA-binding proteins
Zinc finger
A zinc finger is a small, functional, independently folded domain that coordinates one or more zinc ions to stabilize its structure through cysteine and/or histidine residues. Zinc fingers are structurally diverse and exhibit a wide range of functions, from DNA- or RNA-binding to protein-protein interactions and membrane association. [UniProt. (2022, April 28). Zinc finger | UniProt help | UniProt. https://www.uniprot.org/help/zn_fing]First characterized by Miller, McLachlan, and Klug in 1985, the zinc finger (ZF) motif was initially identified in the Xenopus laevis transcription factor IIIA (TFIIIA), a key regulator of gene expression. This highly conserved DNA-binding domain is encoded by about 3% of human genes, making it one of the most abundant protein superfamilies in eukaryotic transcription factors. Structurally, each ZF motif comprises a characteristic α-helix and a two-stranded antiparallel β-sheet, with the fold stabilized by tetrahedral coordination of a Zn2+ ion through conserved cysteine and histidine residues.
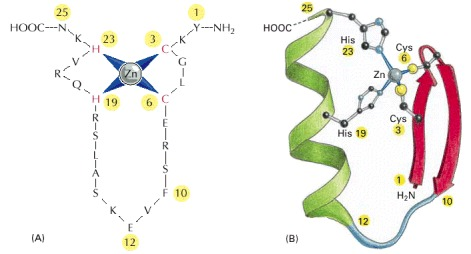
While the zinc ion serves a structural role rather than directly participating in DNA recognition, the N-terminal portion of the α-helix interacts specifically with 3-4 nucleotides in the major groove of DNA. The modularity of zinc finger proteins is particularly noteworthy, as multiple ZF motifs can be linked in tandem arrays through flexible peptide sequences. This architectural flexibility, combined with sequence variations within individual ZF motifs and their connecting linkers, enables recognition of diverse and extended DNA sequences, thus explaining the widespread adoption of this relatively simple structural framework in transcriptional regulation across eukaryotic species.
DNA binding by a zinc finger protein
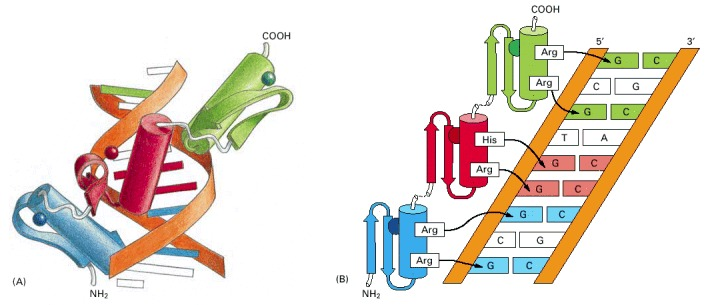
Classes of Zinc finger motif
Three distinct structural classes categorize zinc finger (ZF) motifs, each with unique molecular architectures and metal coordination patterns. The Class I (C2H2) zinc fingers, comprising approximately 25 amino acid residues, feature a canonical fold where two cysteine and two histidine residues coordinate a single Zn2+ ion. This coordination stabilizes a characteristic ββα structure, with the α-helix serving as the primary DNA recognition element. Class II (C4) zinc fingers, approximately 30 residues long, are characterized by four conserved cysteine residues and function as obligate dimers. Each Class II structural unit incorporates two essential helices: a dimerization helix that facilitates protein-protein interactions and a recognition helix that mediates sequence-specific DNA binding within the major groove. The Class III zinc fingers represent a more specialized family characterized by dual zinc coordination through six conserved cysteine residues (C6). Similar to Class II, these motifs employ distinct dimerization and recognition helices for their molecular functions.
Based on their modular organization, zinc finger proteins can be further classified into:
- Single-zinc-finger peptides
- Double-zinc-finger peptides
- Triple-zinc-finger peptides
RNA-Binding Activity
C2H2-type zinc finger proteins exhibit dual nucleic acid recognition capability, binding not only to DNA but also to specific RNA sequences and structural motifs through key residues at positions -1 and +2 of their α-helix, with essential contacts to the phosphodiester backbone facilitating RNA recognition.
Leucine zipper
Leucine zipper domains are made up of two motifs: a basic region that recognizes a specific DNA sequence and a series of leucines spaced 7 residues apart along an α-helix (leucine zipper) that mediate dimerization. Leucine zipper a structural motif that comprises approximately 30 amino acids in an alpha helical confirmation with a repetition of Leu residues at every 7th position. Dimers of leucine zipper proteins recognize short, inverted, repeat sequences. (“Gene Expression,” 2016)Many DNA-binding proteins, including transcription factors like C/EBP, Jun, Fos, GCN4, and HSF, contain the leucine zipper (Eun, 1996). Leucine zipper transcription factors contain leucine residues at every seventh position in the C-terminal end of the DNA-binding domains. These proteins often function as dimers using two extended α-helices to bind DNA at two different major groves. Proteins in this class use basic residues in the α-helix to bind the phosphate groups present in the backbone of DNA in addition to interactions with specific base pairs of the major groove.
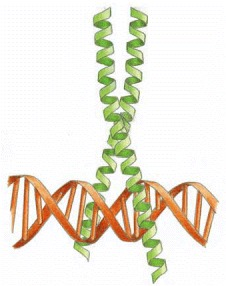
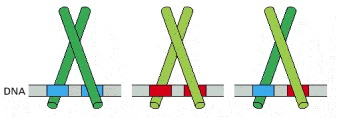
Leucine residue-derived protruding R-groups mediate homo- and heterodimerization through binding interactions with like groups on candidate proteins. Heterodimerization of leucine zipper proteins can alter their DNA-binding specificity and regulate function.
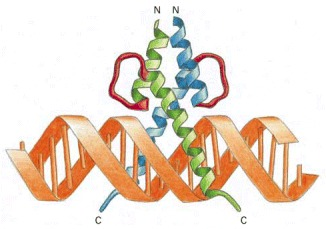
Helix-loop-helix
A Helix Loop Helix Protein is a type of protein that contains a structural motif with 3 alpha helices ( consists of a short α helix connected by a loop to a second, longer α helix), where the third helix acts as a recognition helix interacting with DNA in the major groove. These proteins can be associated with different effector domains to influence various biological processes. The Basic Region Mediates DNA Binding: Adjacent to the HLH motif are located a number of conserved basic residues, consisting mainly of arginines. Deletion of the basic region results in loss of DNA binding, whereas dimerization is not affected. (Murre, 1992)
References
- Hudson, W., Ortlund, E. The structure, function, and evolution of proteins that bind DNA and RNA. Nat Rev Mol Cell Biol 15, 749–760 (2014). https://doi.org/10.1038/nrm3884.
- Ghani, N. S., Firdaus-Raih, M., & Ahmad, S. (2018). Computational prediction of nucleic acid binding residues from sequence. In Elsevier eBooks (pp. 678–687). https://doi.org/10.1016/b978-0-12-809633-8.20662-6.
- Ghosh, I., Yao, S., & Chmielewski, J. (1999). DNA-binding peptides. In Elsevier eBooks (pp. 477–490). https://doi.org/10.1016/b978-0-08-091283-7.00069-2
- Isalan, M. (2004). Zinc fingers. In Elsevier eBooks (pp. 435–439). https://doi.org/10.1016/b0-12-443710-9/00713-4.
- Adhya, S. (2001). Regulatory genes. In Elsevier eBooks (pp. 1652–1657). https://doi.org/10.1006/rwgn.2001.1092.
- Alberts, B., Johnson, A., Lewis, J., Raff, M., Roberts, K., & Walter, P. (2002). DNA-Binding motifs in gene regulatory proteins. Molecular Biology of the Cell – NCBI Bookshelf. https://www.ncbi.nlm.nih.gov/books/NBK26806/
- Murre, C. (1992). The Helix-Loop-Helix Motif. In: Eckstein, F., Lilley, D.M.J. (eds) Nucleic Acids and Molecular Biology. Nucleic Acids and Molecular Biology, vol 6. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-77356-3_6
